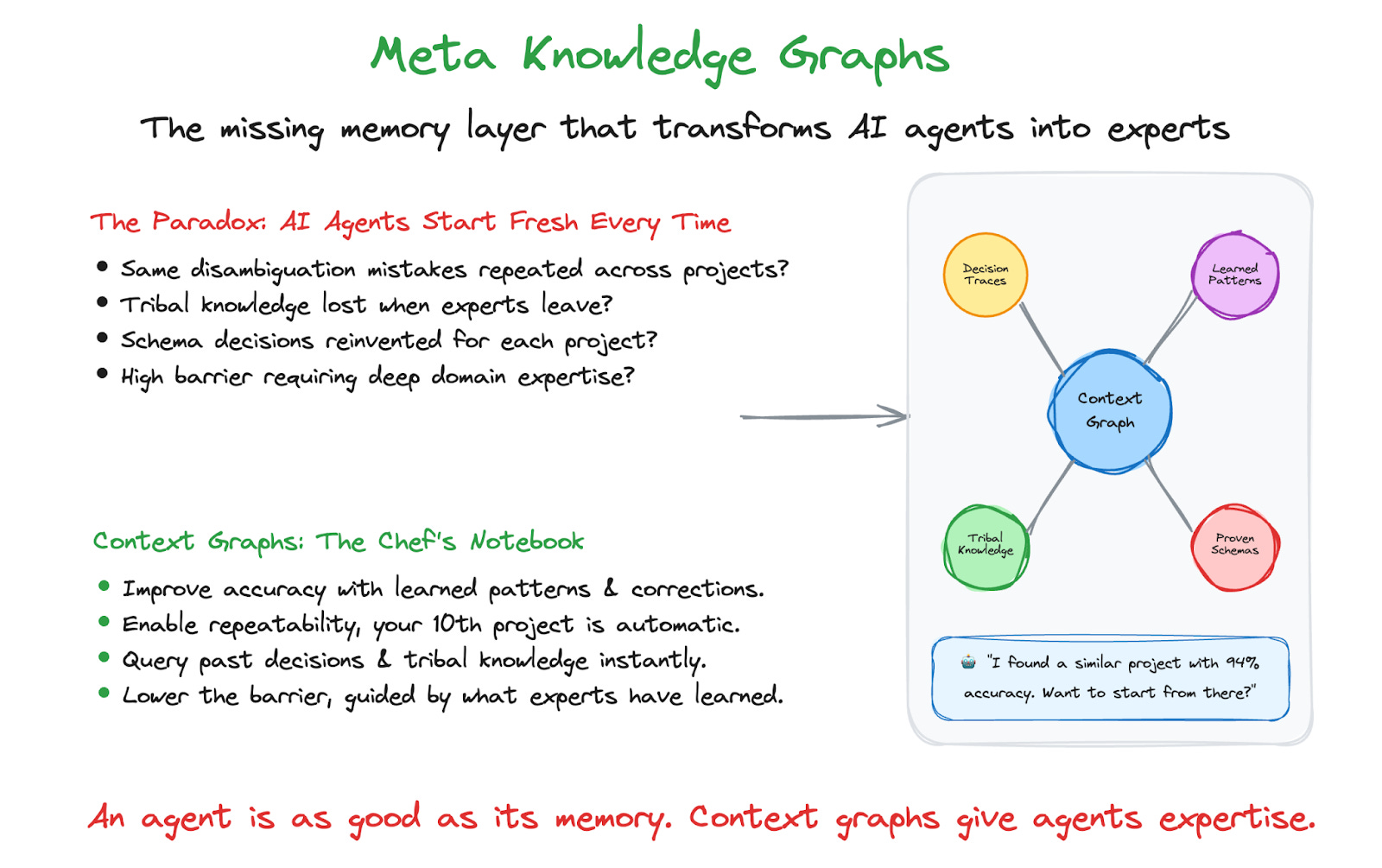
Meta Knowledge Graphs(Context Graphs)
The Memory Graph Layer for Agents

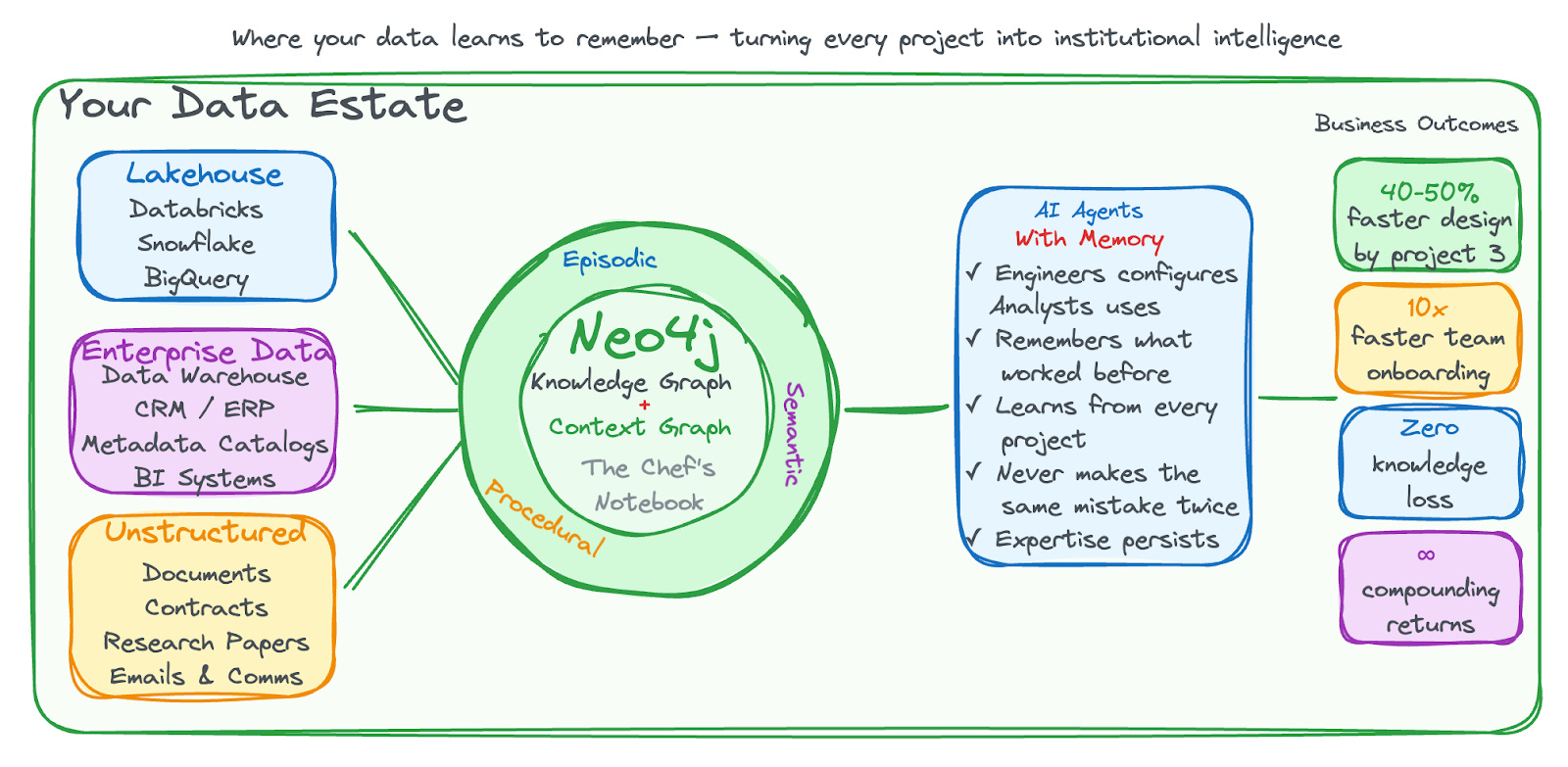
Your data estate, lakehouses, warehouses, and unstructured documents, feeds AI agents every day. But most architectures miss one thing: memory. Every project starts fresh. Every lesson learned evaporates. Neo4j can sit at the centre of your agentic system and data estate as the intelligence layer: a Knowledge Graph that captures what exists, paired with a Context Graph that captures how and why decisions were made. Context graphs help in two places: they improve knowledge graph construction (reuse prior modelling, extraction, and resolution decisions) and they improve retrieval (help agents understand how the graph was built and what patterns worked before). This article focuses on the construction side and connects it back to retrieval along the way.
Introduction
Knowledge graphs have moved from research curiosity to enterprise imperative. Their potential to connect data and power AI applications is now proven. With LLM-powered extraction, organisations can turn unstructured documents into queryable knowledge in hours, not months. The technology works.
But here’s the question I keep coming back to: how do we bring the intelligence of an expert knowledge graph builder to an agent? What separates following a recipe from earning a Michelin star?
Think about what an expert does when they read a contract. They don’t just extract entities, they bring years of accumulated context. They know that “SOW” and “Statement of Work” are the same concept. They know when “provider” is a legal party versus a service type. And they remember that last quarter’s project used a schema and resolution strategy that worked for this exact document set.
An LLM can extract entities from text. But without context, it makes the same disambiguation mistakes over and over. It doesn’t know that your organisation spells it ‘organisation’ not ‘organization.’ It doesn’t know that in your industry, ‘provider’ has a specific regulatory meaning. It doesn’t remember that last week, a domain expert corrected an entity resolution, and that correction should apply to every future document.
The extraction itself isn’t the problem. What’s missing is the accumulated context that separates a first attempt from expert-level accuracy. The ontologies that map equivalent terms. The disambiguation rules learned from corrections. The domain knowledge about what entities mean in your specific context. At the end of the day, a knowledge graph is designed to solve business problems. What’s the problem we are trying to solve? What are the ‘soft’ requirements and constraints that live in an organisation as tribal knowledge distributed across different systems and people?
That context is what separates a one-time extraction from a system that gets better with every document and truly represents your business problem.
The paradox
Here’s the paradox, AI is supposed to learn, but most agents start fresh every time. We can patch gaps with prompts, runbooks, and instructions, but unstructured guidance is hard for software to apply consistently. It’s brittle, it conflicts, and it rarely comes with provenance (“who decided this, why, and when does it stop applying?”). The result is predictable: accuracy stalls, repeatability suffers, and decisions become hard to explain or audit. Unless we capture decision context as structured, queryable memory, a context graph, we keep paying the “first project” cost again and again. Remember, an agent, whether it is a software agent or a human agent, is only as good as its knowledge.
It’s an interesting conundrum. The extraction pipelines are getting better. The entity resolution is improving. But the accumulated wisdom of past projects? It walks out the door when the project ends.
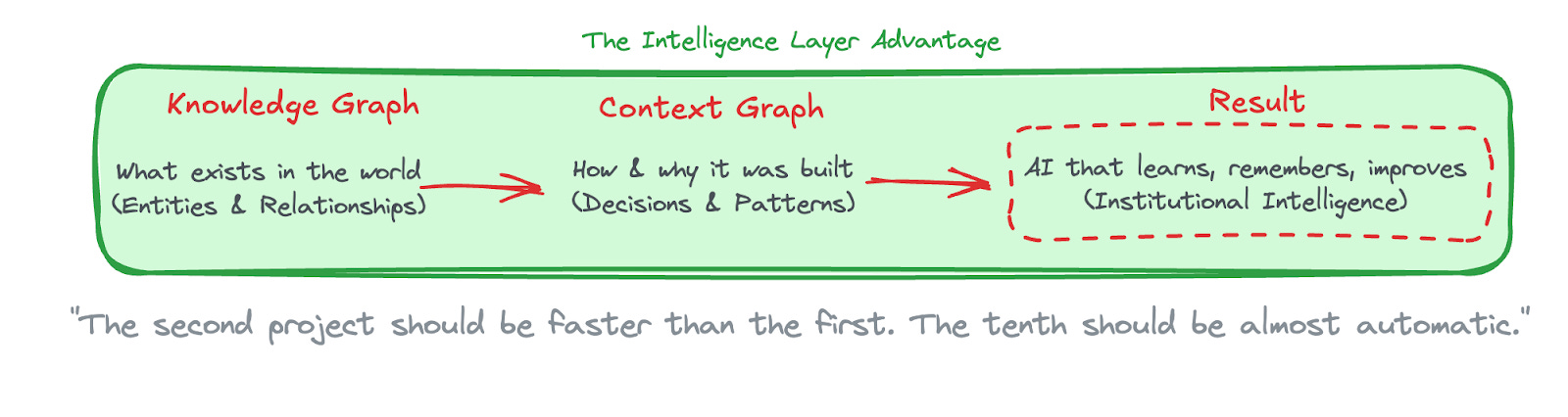
The weird part? A graph is the perfect structure to solve this problem. In a way, we have a (meta/context) graph for a (knowledge) graph. Context graphs extend tools like Neo4j’s Knowledge Graph Builder by persisting decision context that would otherwise live only in run logs and chat sessions, enabling cross-project learning and institutional memory.
The missing ingredient: context
Hear me out here. I have written about this when I led the data agents in BigQuery not so long ago, how AI agents, effectively working like ants, leave trails for others to follow, how they find the shortest path to value. That thinking applies directly to knowledge graphs.
Think about what separates a good chef from a great one.
A good chef can follow a recipe. Dice the onions, sauté for five minutes, add the stock. But a great chef brings something else entirely. They know what time of year it is and which ingredients are at their peak right now. They know who their suppliers are and how dependable they are. They understand what problem they’re solving for tonight’s service: is this a celebration dinner or a quick weeknight meal? They understand the profile of their customers and what the expectations would be. Over years of practice, they’ve learned how to coax the best out of what they have in the environment they operate in. When the delivery arrives with smaller shallots than expected, they adjust instinctively.
That expertise isn’t written in any recipe book. You can’t learn it from reading alone. It’s why you don’t earn a Michelin star by following instructions. It requires knowledge, skill, and years of accumulated judgment that compounds over time.
Knowledge graph generation works the same way. The LLM extraction pipeline is the recipe. But the expertise, knowing which ontology applies to this domain, remembering that these two entity names refer to the same thing, understanding why the last project chose this schema over that one, that’s what separates adequate from excellent.
A context graph is the chef’s notebook. It captures not just what was built, but how, why, and what to do differently next time. It’s the chemical trail (like ants leave) that makes the next project better than the last. In graph terms, this trail is a chain of relationships connecting decisions across the organisation, queryable to find “all decisions similar to this one.”
A note on observability integration: if you already use agent tracing/observability tools that capture conversation logs, tool calls, and execution metadata, you’re halfway there. Those traces record what happened: inputs, outputs, timing, and sequence. Context graphs add why it happened: rationale, alternatives considered, and the domain knowledge that informed the choice.
The opportunity is to enrich traces with decision objects at creation time, and feed outcomes back into the context graph as learning signals. Success becomes precedent. Corrections become patterns. Over time, observability data feeds your intelligence layer, and your intelligence layer improves what you observe.
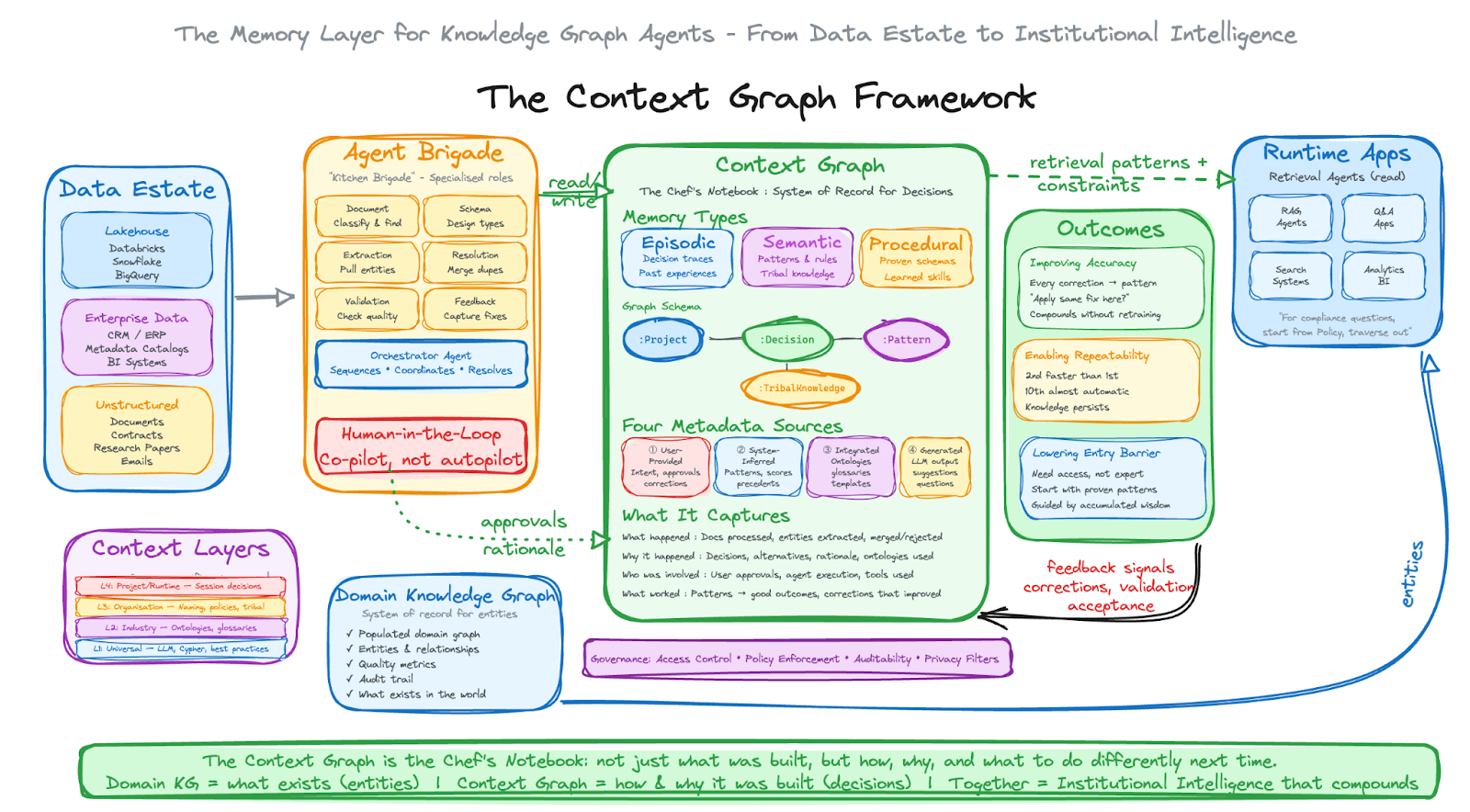
Here’s the whole framework in one view. A domain knowledge graph records what exists. A context graph records how and why it was built, decisions, provenance, and reusable patterns. The agent “kitchen brigade” reads from both and writes to both, so each project starts with precedent instead of guesswork.
What do we mean by context graph?
Before the technical definition, let’s be clear about what we’re really building: an organisational intelligence layer. Enterprise know-how doesn’t live only in documents or tables. It shows up as connected metadata:
Technical metadata: schemas, lineage, pipeline steps, extraction/evaluation runs
Business metadata: glossary meaning, ownership, intended use, policy and regulatory constraints
Operational metadata: quality checks, incidents and mitigations, SLAs, cost/performance budgets
Most organisations store these in separate places, catalogs, glossaries, runbooks, tickets. The connections live in people’s heads. When teams change, that know-how doesn’t transfer cleanly. A context graph weaves these metadata types together with decision context from graph construction: what was chosen, why it was chosen, what alternatives were considered, and what outcome it produced.
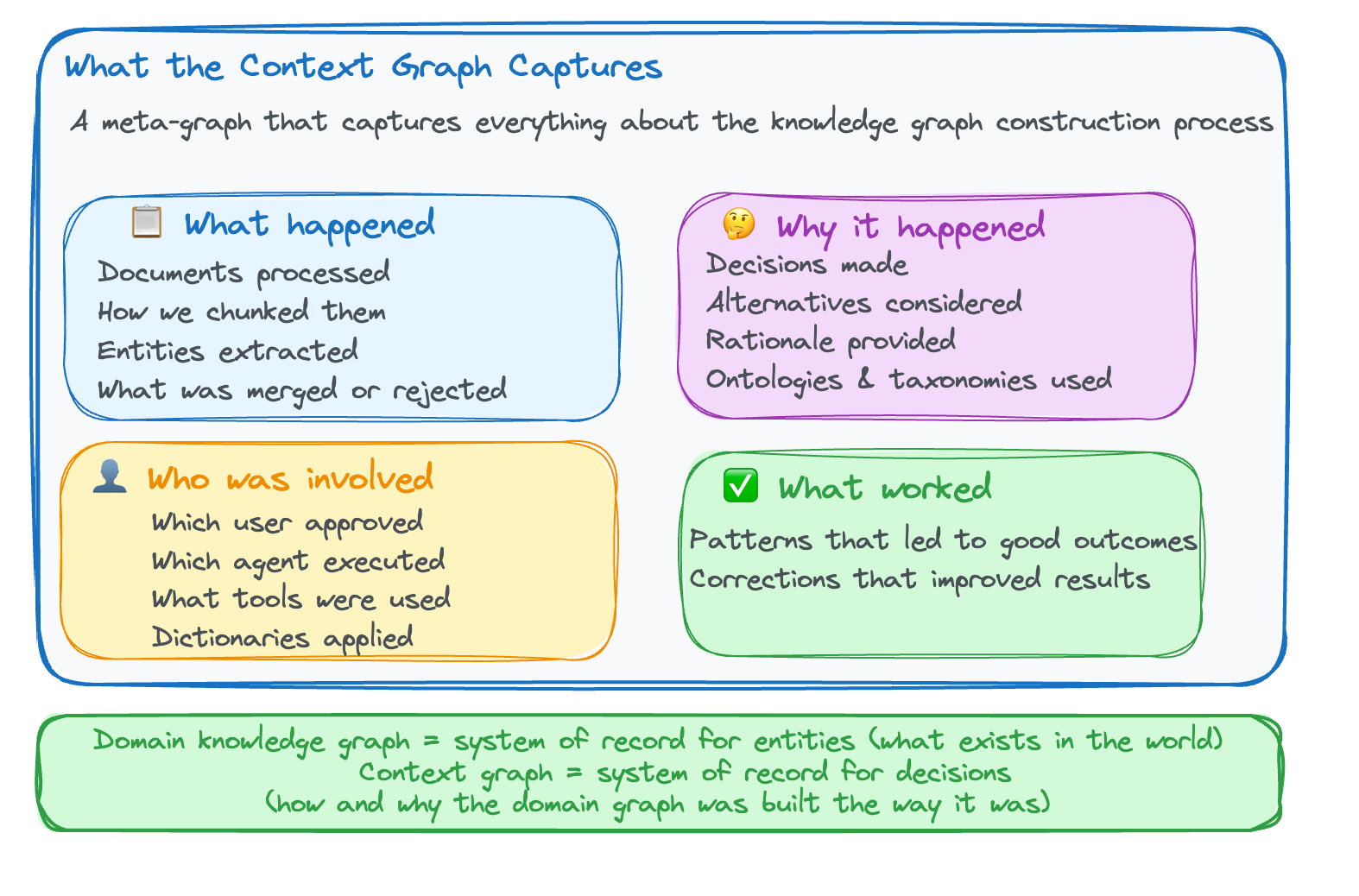
So a context graph is a meta-graph that captures everything about the knowledge graph construction process:
What happened: Which documents were processed, how we chunk the documents, what information we expect in this domain, what entities were extracted, what was merged or rejected
Why it happened: The decisions made, alternatives considered, rationale provided, ontologies and taxonomies used
Who was involved: Which user approved, which agent executed, what tools and dictionaries used
What worked: Patterns that led to good outcomes, corrections that improved results
The domain knowledge graph is a system of record for entities: what exists in the world.
The context graph is a system of record for decisions: how and why the domain graph was built the way it was.
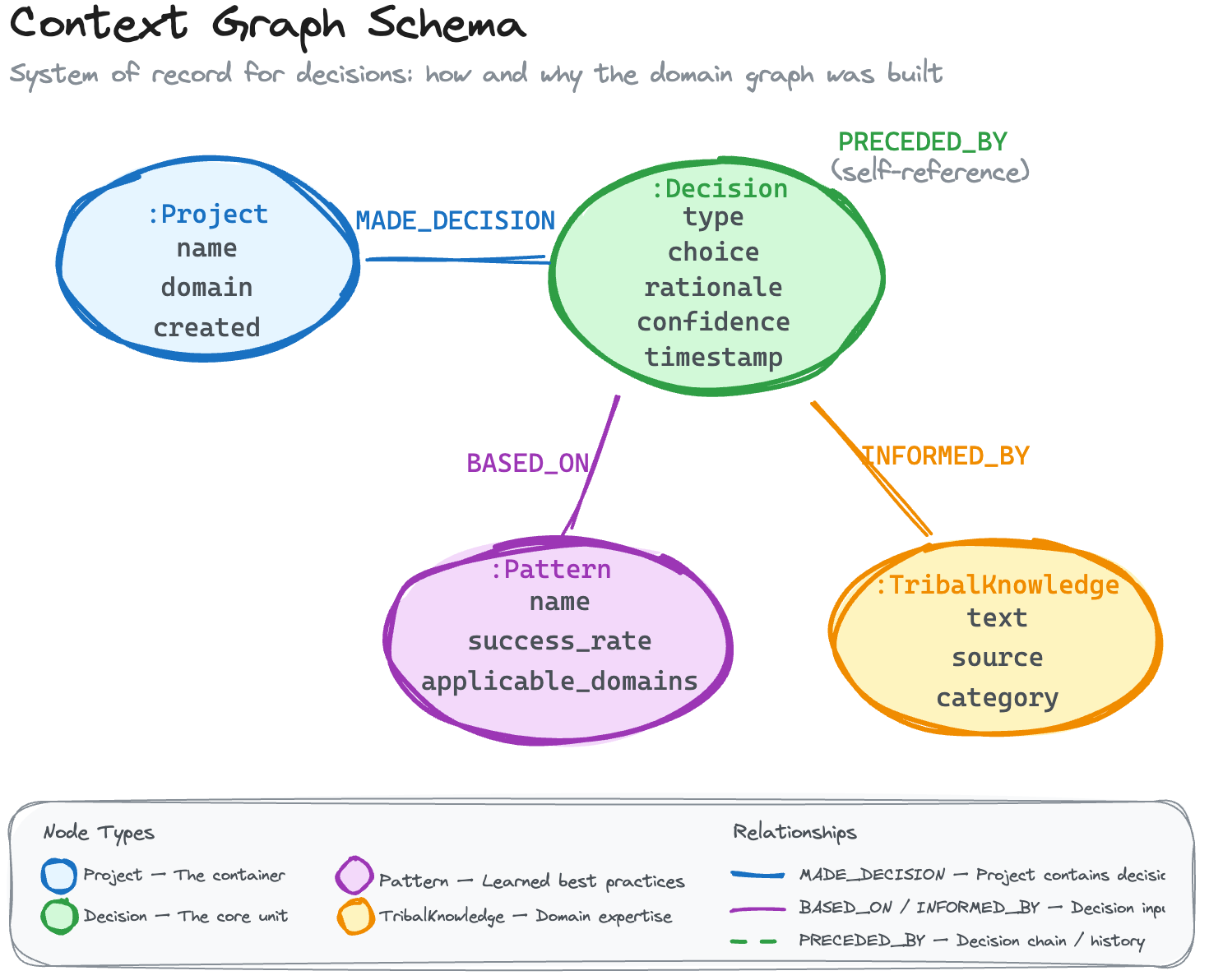
The context graph can be implemented as a separate graph database or as a labeled subgraph within the same Neo4j instance, using labels like :Decision, :Pattern, and :TribalKnowledge to distinguish meta-nodes from domain nodes.
A simple schema example:
(:Project {name, domain, created_at})
(:Decision {type, choice, rationale, confidence, outcome, schema_version, timestamp})
(:Pattern {name, success_rate, applicable_domains})
(:TribalKnowledge {text, source, category})
(:Project)-[:MADE_DECISION]->(:Decision)
(:Decision)-[:BASED_ON]->(:Pattern)
(:Decision)-[:INFORMED_BY]->(:TribalKnowledge)
(:Decision)-[:PRECEDED_BY]->(:Decision)
Agents have short-term memory that works within a session. But they also need long-term memory: the metadata, the context, the best practices. What graph models work for this domain? What entity types have succeeded? What quality thresholds made sense? What patterns should we reuse?
This isn’t about fine-tuning the LLM or expanding its context window. It’s about maintaining a structured, queryable knowledge base of past decisions that agents retrieve at inference time. The system accumulates patterns, not through retraining, but through indexed decisions that agents query and apply. This is what gives an agent its intelligence.
This brings us to a question: if context graphs provide memory, what kind of memory? The answer comes from cognitive science.
Context graphs as agent memory
Large language models cannot, by themselves, remember things. The memory component must be added, but not all memory approaches solve the same problem. Vector or summary based memory is great for recalling relevant snippets of text. Knowledge graph construction needs something else: durable, auditable precedent. Decisions in one step affect later steps (schema choices affect extraction; extraction affects resolution; resolution affects downstream quality). You want to reuse the *decision structure*, not just the text of a prior conversation.
Why graphs? Three reasons:
Explicit relationships. Context graphs store links (decision → rationale → evidence → outcome) as first-class objects you can query and govern, rather than implicit associations you hope similarity search will recover.
Multi-hop reasoning. Expertise is chained inference: “this document type implies this schema; this schema implies these entity types; those entity types have known disambiguation pitfalls; here’s the fix that worked last time.”
Provenance & evolution. Graphs make it natural to version decisions, attach who-approved-what, and track what changed when outcomes improve or requirements shift.
Context graphs provide this memory layer, and they map directly to established AI memory paradigms from cognitive science. Recent research has begun systematically examining agent memory architectures. Surveys such as Hu et al. (2025) propose complementary frameworks organised around forms (how memory is stored), functions (why memory is needed), and dynamics (how memory evolves). Within this landscape, context graphs occupy a specific position: they are token-level memory in form (explicit, graph-structured, queryable), serving both factual and experiential functions (capturing what happened and what worked), with dynamics driven by the knowledge graph construction lifecycle.
What distinguishes context graphs is their application to a meta-level problem. Let me explain what that means.
Most agent memory systems help agents remember things about the world: customer preferences, conversation history, factual knowledge. The agent uses this memory to complete tasks better.
Context graphs operate one level up. They help agents remember how to build representations of the world. Not “what entities exist in this document,” but “how should I approach extracting entities from this type of document, given what worked before?” Not “what is the relationship between these nodes,” but “which relationship types have proven useful for this domain and why?”
This is the difference between a chef remembering ingredients and a chef remembering how to develop recipes. The former is knowledge; the latter is meta-knowledge. Context graphs capture the accumulated expertise that transforms a capable extraction pipeline into an expert system.
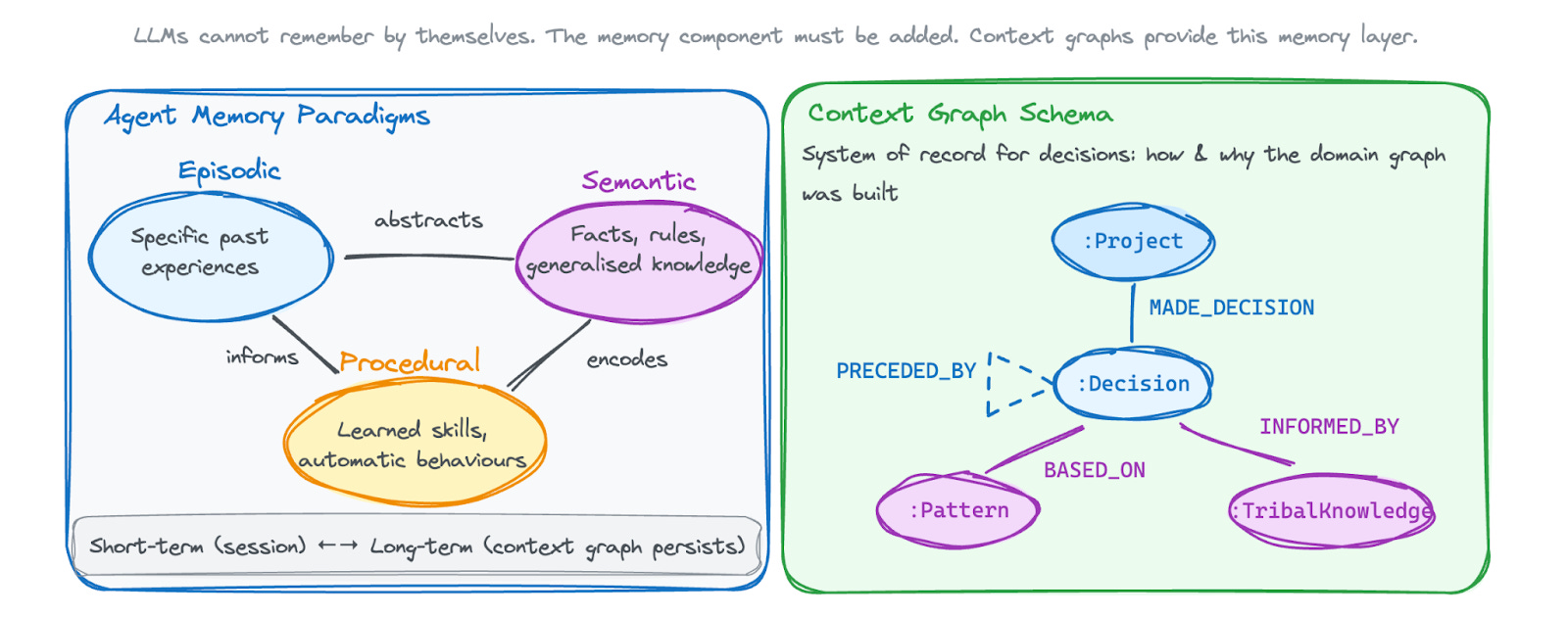
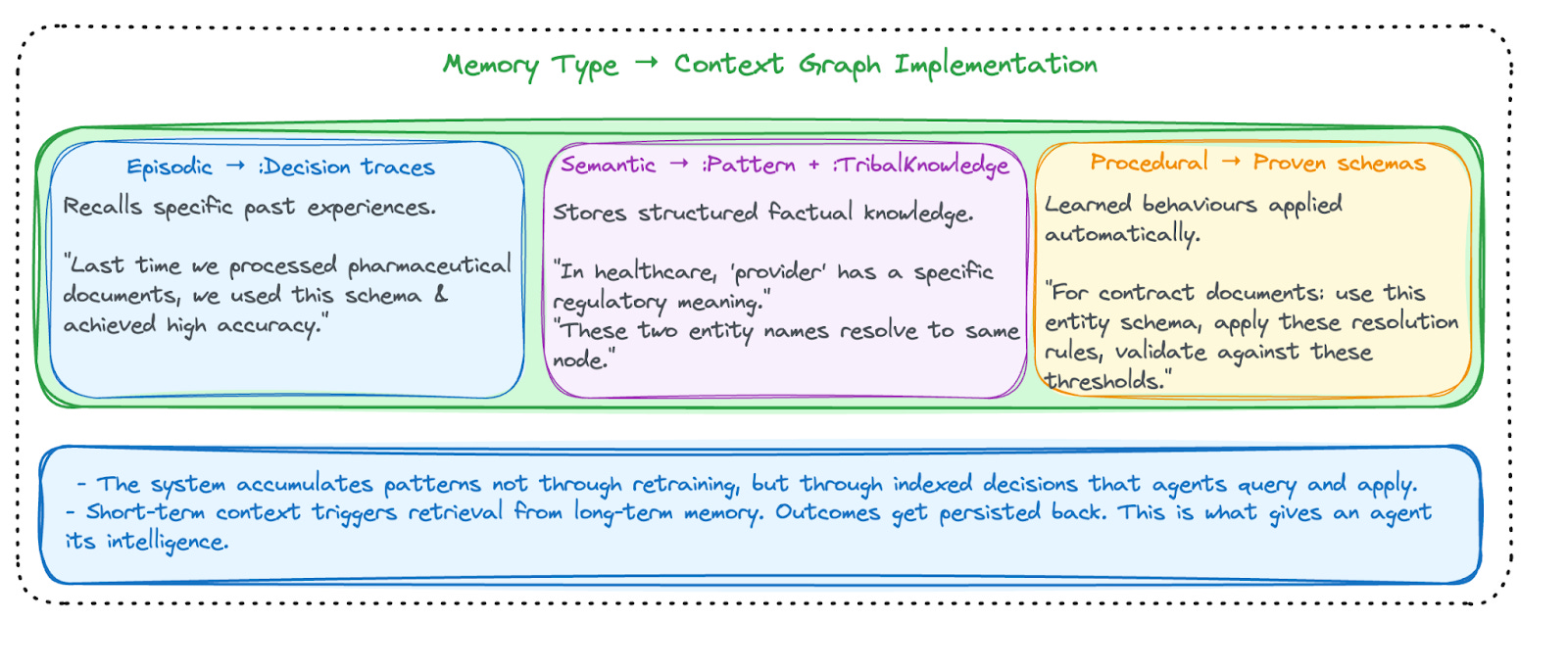
Episodic Memory: Decision Traces
Episodic memory allows agents to recall specific past experiences. In a context graph, decision traces serve this function. Each trace records a specific event: what was decided, what inputs were considered, what the outcome was. When an agent encounters a similar situation, it can retrieve relevant episodes. ‘Last time we processed pharmaceutical documents, we used this schema and achieved high accuracy.’ This is case-based reasoning: learning from past events to make better decisions in the future.
Semantic Memory: Patterns and Tribal Knowledge
Semantic memory stores structured factual knowledge: facts, definitions, and rules. In the context graph, this manifests as patterns, ontologies, and tribal knowledge nodes. ‘In healthcare, provider has a specific regulatory meaning.’ ‘These two entity names should resolve to the same node.’ These are generalised facts that agents retrieve and use for reasoning, independent of any specific project or episode.
Procedural Memory: Proven Schemas and Resolution Strategies
Procedural memory stores learned behaviours and skills, enabling agents to perform tasks automatically without explicit reasoning each time. In context graphs, procedural memory translates to proven schema templates, extraction sequences, and resolution strategies. When an agent encounters a contract document, it doesn’t reason from first principles. It retrieves the procedure: “For contract documents, use this entity schema, apply these resolution rules, validate against these quality thresholds.”
What makes graphs essential here is that procedures have structure. A resolution strategy isn’t a single fact, it’s a sequence with conditions, branches, and dependencies: “If entity type is Person and confidence is below threshold, check against the directory; if match found, merge with a confidence boost; otherwise flag for review.” That’s a graph: steps as nodes, transitions as edges, conditions as properties. Simpler memory systems can store that a procedure exists. Graphs can store how it works, making it queryable, composable, and adaptable across domains.
Long-term vs Short-term Memory
The context graph itself is long-term memory, persisting across sessions and projects. Short-term memory exists at the runtime layer (Layer 4 in our hierarchy), holding immediate context for the current extraction run. The power comes from the interaction: short-term context triggers retrieval from long-term memory, and outcomes from short-term sessions get persisted back into long-term storage.
The building blocks
The context graph draws from four metadata sources:
User-Provided
What humans explicitly contribute. Intent, constraints, approvals, domain expertise (’in our industry, facility means manufacturing plant’), corrections with rationale, references to past projects.
System-Inferred
What the system learns automatically. Schema patterns, confidence scores, precedent matching, success correlations across projects.
Integrated
External knowledge brought in. Ontologies (OWL, SKOS), domain glossaries, graph model templates, business rules documents, and inputs from existing metadata catalogs.
Generated
What agents and LLMs create. Entity extraction, disambiguation, proactive questions at decision points, suggestions based on history.
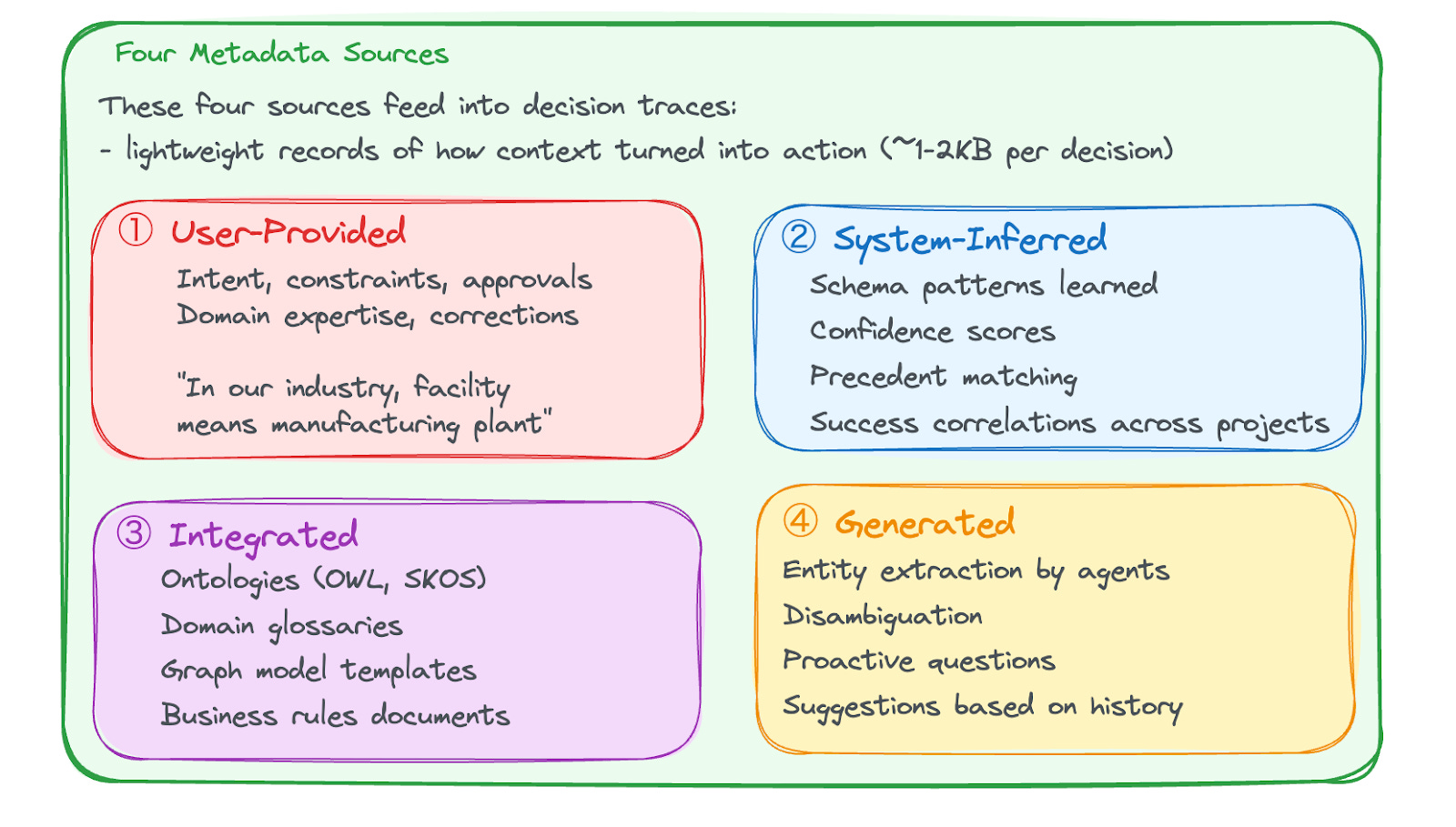
These four sources feed into decision traces: lightweight records of how context turned into action. A decision trace typically captures decision type, inputs considered, choice made, confidence score, user override (if any), and timestamp. A decision trace is intentionally lightweight, small enough to store at high volume, but structured enough to answer: “How did we handle this before?”
Why multi-agent systems matter
Let’s assume knowledge graph construction is handled by a graph-builder system. In practice, that “agent” isn’t a single entity, it’s a set of specialised agents working together, like a kitchen brigade:
Document Agent: Classifies incoming documents, identifies similar past projects and processes the documents
Schema Agent: Designs entity and relationship types, logs decisions and rationale
Extraction Agent: Pulls entities from text, tracks confidence, logs edge cases
Resolution Agent: Merges duplicates using learned strategies, captures overrides
Validation Agent: Checks quality against rules, identifies patterns
Feedback Agent: Captures corrections, surfaces tribal knowledge, updates the context graph
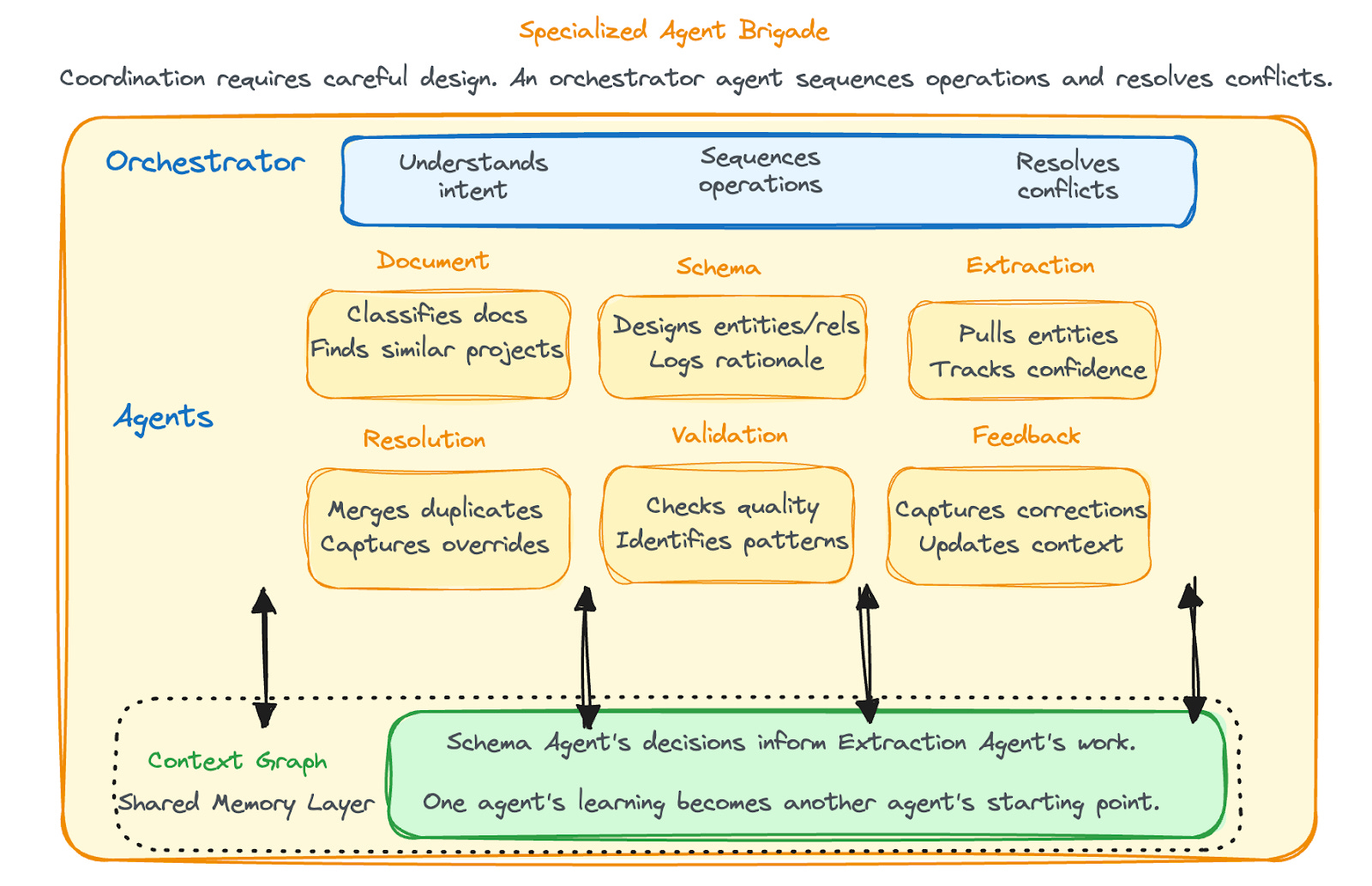
Each agent focuses on a specific subset of the task. They all understand the context, your data, your goals, and your existing workflows, not to mention your organisation’s access and security policies.
Coordination requires careful design. Agents must acquire locks or use event-driven patterns to avoid conflicting writes to the shared context graph. In practice, an orchestrator agent sequences dependent operations and resolves conflicts.
The context graph is what ties them together. It’s the shared memory where the Schema Agent’s decisions inform the Extraction Agent’s work. One agent’s learning becomes another agent’s starting point.
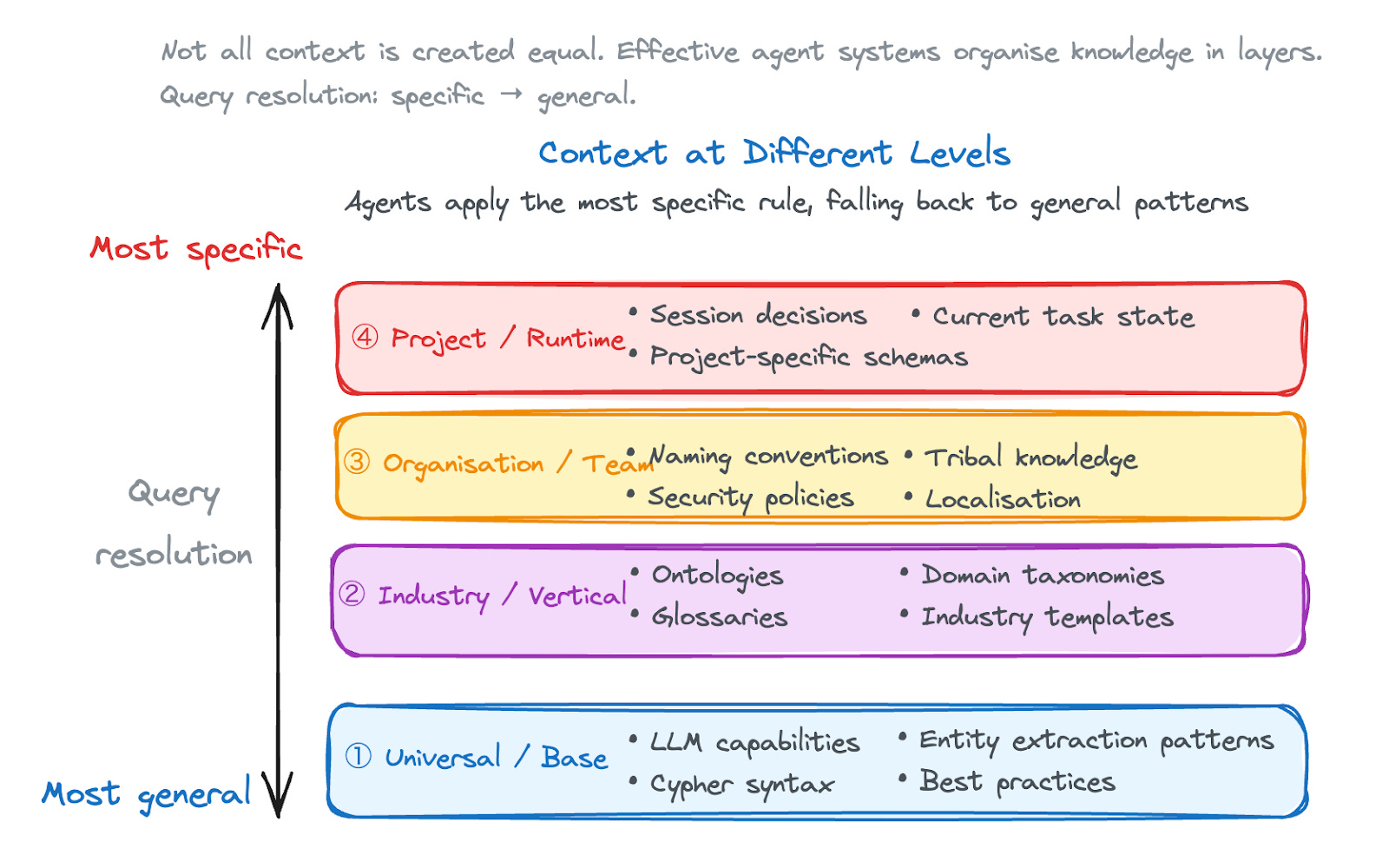
Context at different levels
Not all context is created equal. Effective agent systems organise knowledge in layers, from universal best practices down to project-specific decisions. When an agent needs guidance, it queries from most specific to most general and applies the first applicable rule it finds.
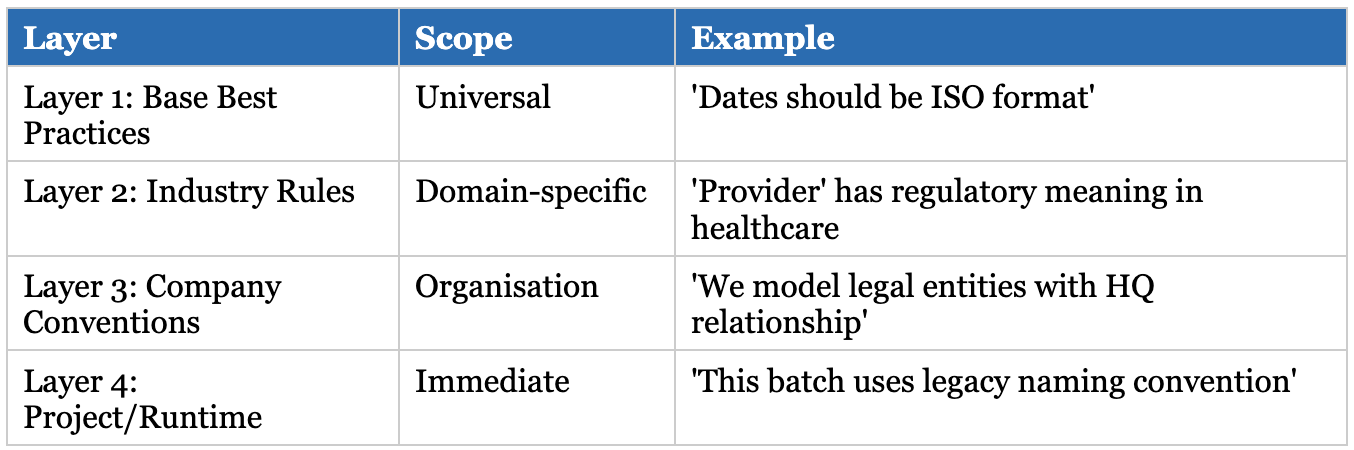
These layers translate directly to graph structure: global nodes for base practices, industry-labeled subgraphs, organisation-scoped contexts, and project-level runtime state. The query pattern is simple: start specific, fall back to general. If no project rule exists, check organisation conventions. If none there, apply industry standards. If nothing matches, use universal best practices.
This layered approach means a new project in healthcare automatically inherits both your company’s naming conventions and standard medical ontologies. All of this happens without anyone having to configure it.
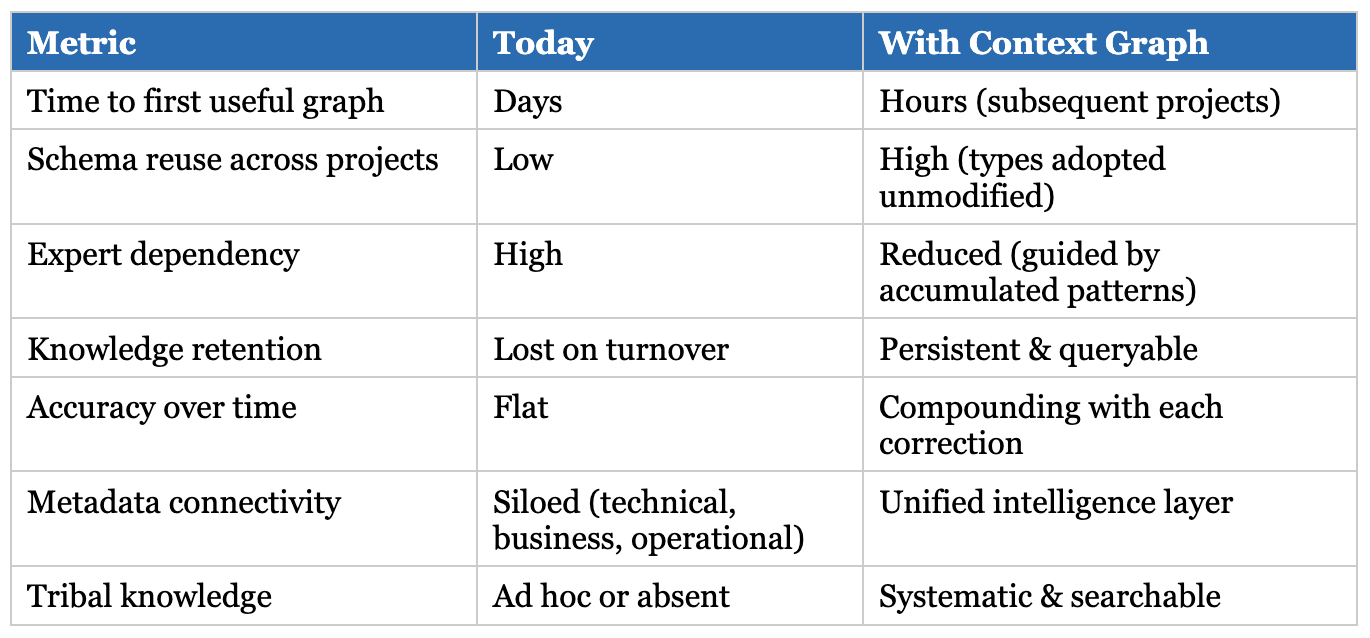
Three outcomes that matter
Improving accuracy
Every correction captured in the context graph makes future extractions better. When a user fixes an entity classification, that fix becomes a pattern. When a domain expert clarifies that ‘ACME’ and ‘Acme Corp’ are the same entity, that resolution rule persists.
The agent can say: ‘Last time you corrected this pattern. Should I apply the same fix here?’ Over time, the system accumulates patterns of what ‘right’ looks like for your domain, not through retraining, but through indexed corrections that agents retrieve and apply.
Enabling repeatability
The second project should be faster than the first. The tenth should be almost automatic.
With a context graph, the agent can suggest: ‘I found a similar project with a high validation pass rate. Here’s the schema they used. Want to start from there?’ You’re not reinventing decisions. You’re building on what worked.
Here’s an example of how an agent retrieves proven patterns:
MATCH (p:Project {domain: $domain})-[:MADE_DECISION]->(d:Decision)
WHERE d.type = ‘schema_choice’ AND d.outcome = ‘success’
RETURN d.choice, d.rationale, count(*) AS frequency
ORDER BY frequency DESC LIMIT 5
When the original expert moves on, the knowledge doesn’t leave with them. The decisions, the rationale, the tribal knowledge: it’s all in the graph.
Lowering the entry barrier
Today, building a quality knowledge graph often requires deep domain expertise and months of trial and error. Context graphs change that equation.
A new team member can start with proven patterns. An analyst who isn’t a graph modelling expert can still build something useful because the agent guides them based on what’s worked before. The barrier shifts from ‘you need an expert’ to ‘you need access to what experts have learned.’
For new deployments, the context graph starts with integrated sources: ontologies, industry templates, and curated best practices. The system becomes more valuable as projects accumulate, but it provides value from day one through these starting points.
Beyond construction: context graphs for retrieval
While this article focuses on building knowledge graphs, the same idea applies when agents query them. Retrieval also benefits from precedent: which traversal patterns work for this kind of question, what disambiguation rules apply, and what “good answers” looked like in similar situations.
A context graph can capture retrieval patterns just as it captures construction patterns: “For compliance questions, start from Policy and traverse outward,” or “When users ask for relationships, prefer path queries over isolated lookups.” If certain query patterns consistently disappoint, that feedback becomes a signal to adjust either retrieval strategy or the underlying schema. In other words: the domain graph captures what exists; the context graph captures how you build it and how you use it, so the system improves with every build, query, and correction.
What’s in it for me?
The value proposition is simple: every project makes the next one easier, but it’s worth being explicit about what compounds. Context graphs turn tribal knowledge into an asset: the unwritten rules, the exceptions, the “everyone knows that” assumptions, and the corrections that never make it into formal documentation. Instead of rediscovering those lessons through trial and error, teams start from precedent: decisions linked to outcomes. For data engineers, this means less rework and faster graph bootstrapping. For analysts, it means guided paths to quality graphs. For governance teams, it means traceable rationale. For leadership, it means institutional memory that doesn’t walk out the door.
Governance and guardrails
Automating these capabilities demands a commitment to security, privacy, and responsible AI principles. Every AI agent must operate within your existing governance frameworks.
The context graph supports this with:
Privacy Controls: Option to exclude sensitive information from decision traces
Policy Enforcement: Agents operate within defined boundaries; exceptions require approval
Human-in-the-Loop: Co-pilot, not autopilot. The agent proposes, humans approve. Suggestions are informed starting points, not automatic overrides
Audit Trail: Immutable logs of who decided what, when, and why
Access Control: Project-level, organisation-level, or role-based visibility
Handling schema evolution
Context graphs must handle schema evolution. When source systems change or requirements shift, the system should flag affected decisions and suggest updates, not blindly apply outdated patterns. Version tracking on decision traces enables this: each decision records the schema version it was made against, and agents can detect when patterns may be stale.
Scale considerations
At enterprise scale, context graphs may contain millions of decision nodes. Indexing on decision type, timestamp, and project ID ensures sub-100ms query times for pattern retrieval. Archival strategies move older decisions to cold storage while preserving frequently-referenced patterns.
And, crucially, this isn’t about replacing knowledge graph professionals; it’s about uplifting them. With routine decisions handled by agents drawing on accumulated wisdom, experts can focus on the complex modelling challenges, the edge cases, and the strategic initiatives that actually require human judgment.
What good looks like
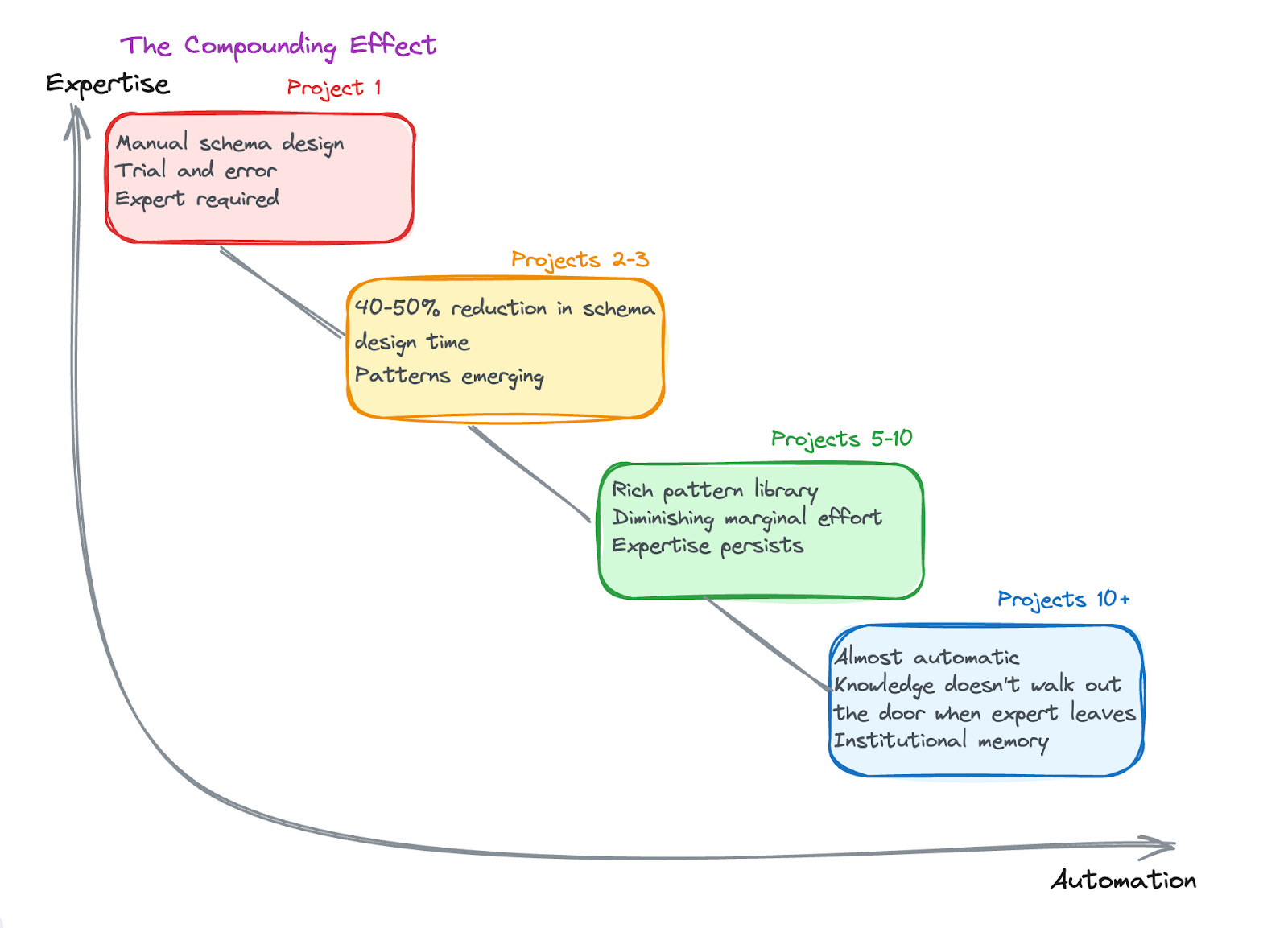
The compounding effect matters most. Every project makes the next one easier. Every correction improves future extractions. Every captured decision becomes a searchable precedent.
To recap
Context graphs are the missing memory layer for knowledge graph agents. They implement the full spectrum of agent memory: episodic memory through decision traces, semantic memory through patterns and tribal knowledge, and procedural memory through proven schemas and resolution strategies. They’re the chef’s notebook, the accumulated expertise that separates following a recipe from earning recognition.
They enable:
Better accuracy through learned patterns, disambiguation rules, and captured corrections
True repeatability so success isn’t dependent on who built it
Lower barriers so more people can build quality graphs
The shortest path to value?
Start capturing decision traces now, even before the full context graph is built. Every schema choice recorded, every correction logged, every rationale captured is memory that compounds over time. An assistive agent can help you capture this knowledge: the context you share through chat, the clarifying questions you answer. These conversations hold valuable information that often goes unrecorded. A knowledge graph is a living thing. Just like us, we learn and update our understanding with each iteration. Software agents powered with context graphs do the same.
The best time to build a context graph was when you started your first knowledge graph project. The second best time is today.
References
1. Hu, Y., Liu, S., Yue, Y., et al. (2025). ‘Memory in the Age of AI Agents: A Survey — Forms, Functions and Dynamics.’ arXiv:2512.13564. Comprehensive survey establishing the forms-functions-dynamics taxonomy for agent memory systems.
2. Park, J.S., O’Brien, J.C., Cai, C.J., et al. (2023). ‘Generative Agents: Interactive Simulacra of Human Behavior.’ Stanford University. Seminal work demonstrating memory-enabled agents in social simulation, introducing reflection and memory retrieval patterns.
3. Shinn, N., Cassano, F., et al. (2023). ‘Reflexion: Language Agents with Verbal Reinforcement Learning.’ Introduced experiential memory through self-reflection, distinguishing short-term trajectory memory from long-term feedback memory.
4. Packer, C., Wooders, S., et al. (2023). ‘MemGPT: Towards LLMs as Operating Systems.’ Influential memory architecture using an operating system metaphor for hierarchical memory management.
5. Zhao, A., Huang, D., et al. (2024). ‘ExpeL: LLM Agents Are Experiential Learners.’ Demonstrated how agents can extract insights and few-shot examples from past experiences for cross-task learning.
6. Tulving, E. (1972, 2002). ‘Episodic and Semantic Memory’ in Organisation of Memory; ‘Episodic Memory: From Mind to Brain.’ Annual Review of Psychology. Foundational cognitive science framework distinguishing episodic (event-specific) from semantic (generalised fact) memory.
7. Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models” (arXiv:2510.04618, Oct 2025).