Building the Meta Knowledge Graph: Four Metadata Categories and the Architecture That Connects Them
Everyone is racing to solve the same problem: how do you give AI agents the context they need without dumping everything into the context window?

Enterprise Data Architecture for the Agentic Era, Part 2 of 3
This is the second in a three-part series. Part 1 introduced the “context wall” and the case for a meta knowledge graph with three types of agent memory. Part 3 covers the metamodel, governance, and getting started. My previous article on context graphs planted the seed.
Recap: from context wall to context engineering
In Part 1, I argued that AI agents fail in enterprise environments not because the models are weak but because the data architecture was built for humans, not machines. The “context wall” explains why demos work and production stalls. The solution is context engineering: building a meta knowledge graph that agents read from, write to, and learn through. That article covered the three types of memory agents need: short-term (the current session), long-term (enterprise knowledge), and reasoning memory (decision traces and corrections).
This part covers what goes into the meta knowledge graph and how the architecture works. To return to the Michelin kitchen analogy: Part 1 was about why the restaurant needs a shared memory. This part is about what’s on the shelves, how the kitchen is organised, and why you don’t need to rebuild the building to start.
Four Metadata Categories, Implemented as Connected Subgraphs
The meta knowledge graph must harvest metadata across multiple dimensions. Most organisations capture only the visible portion (schemas and lineage), while the deeper context that agents actually need remains hidden. What follows is not a rigid taxonomy. Depending on your organisation’s maturity, categories will overlap and some will carry more weight. What matters is comprehensiveness and connectivity.
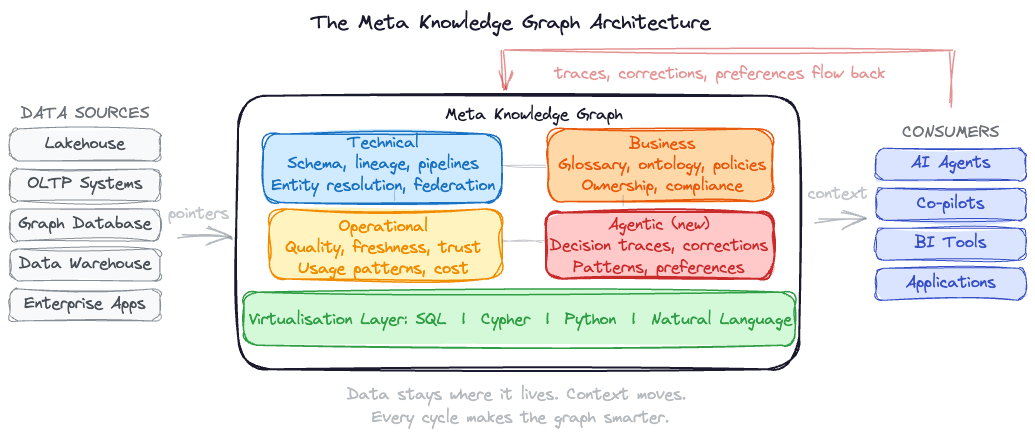
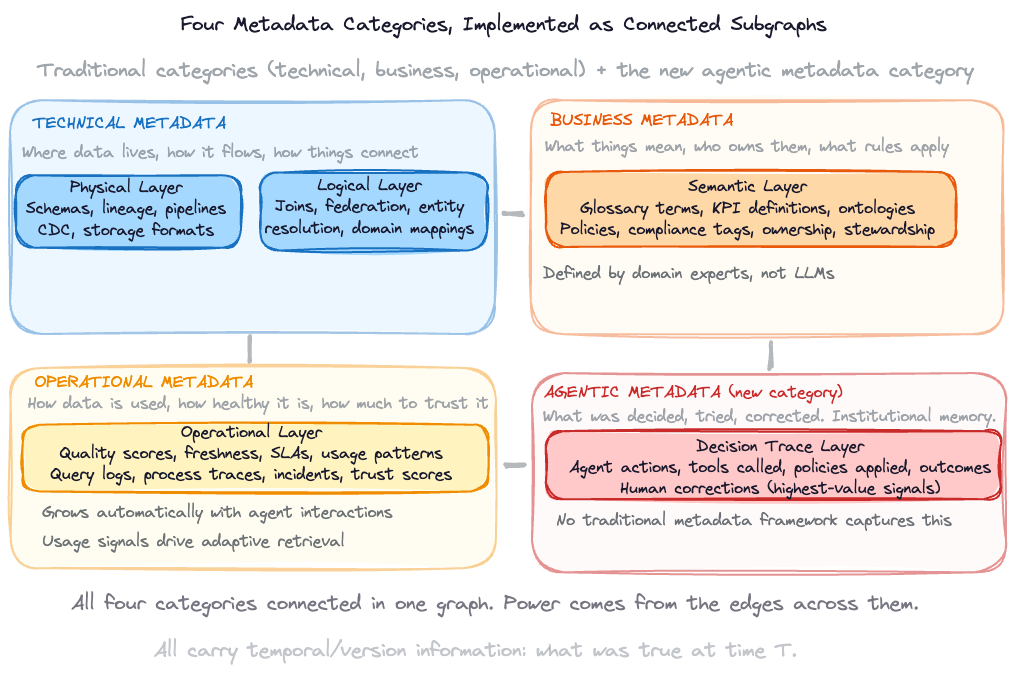
Enterprise metadata has traditionally been organised into three broad categories: technical metadata (schemas, lineage, pipeline mechanics), business metadata (glossary terms, KPI definitions, ownership, policies), and operational metadata (quality scores, freshness, SLAs, incidents). These categories remain the foundation, and most metadata tools and frameworks are built around them. But they are not sufficient for the agentic era.
What’s missing is a fourth category, which I’ll call agentic metadata: the metadata that agents themselves generate and consume. Decision traces, confidence scores, tool invocation logs, and the accumulated patterns of what worked and what didn’t. No traditional metadata framework captures this, because until now there were no agents producing it. Agentic metadata is what closes the learning loop and transforms a static metadata catalog into a living intelligence layer. You can think of this as reinforcement learning accumulating and iterating over time. It works like ants in nature: each ant leaves a chemical trail (a pheromone) marking the route it took. Other ants follow stronger trails, reinforcing successful paths and letting unsuccessful ones fade. The meta knowledge graph works the same way: every successful agent run strengthens the patterns in the graph, every correction redirects future agents, and over time the system converges on the most effective paths through the organisation’s data and knowledge.
The layers below span all four categories. They also map directly to the memory types from Part 1. Long-term memory, the accumulated enterprise knowledge, is served by three metadata categories: technical metadata tells agents where data lives and how it connects; business metadata tells agents what it means; operational metadata tells agents how healthy and trustworthy it is. Agentic metadata, the fourth category, serves reasoning memory: the decision traces, corrections, and preferences that accumulate as agents and humans work together. Short-term memory operates at runtime and feeds its outcomes back into the persistent layers when sessions conclude.
For quick reference:
Technical metadata is covered by the Physical Layer (where data lives, how it flows) and the Logical Layer (how things connect across systems, entity resolution, federation).
Business metadata is covered by the Semantic Layer (what things mean, business terms, ontologies, policies, compliance tags, ownership).
Operational metadata is covered by the Operational Layer (data health, freshness, quality, lifecycle, usage patterns, process traces).
Agentic metadata is covered by the Decision Trace Layer (agent reasoning, human corrections, precedent, accumulated experience).
And across all layers, temporal and version information should be maintained. When schemas change, when definitions evolve, when policies are updated, the graph should preserve that history so agents can reason about what was true at a given point in time, not just what is true now.
Technical Metadata: The Physical and Logical Layers
The Physical Layer is the structural foundation. For agents, it answers: “Where does this data live, where did it come from, and how does it get here?”
What to capture: table and collection schemas, column definitions and data types. Data lineage from ingestion through transformation to consumption, including streaming data flows (event topics, producers, consumers). Pipeline definitions and orchestration dependencies. Storage formats and change data capture configurations.
In principle, this layer should be harvested, not manually built. In practice, that’s rarely the reality. Metadata is usually seen as a “nice to have” when time pressures hit deliveries. Humans under pressure to ship the pipeline will skip documenting it. This is where agent-driven data engineering changes the equation: automated software is inherently better at capturing and registering its own actions than a human who is juggling ten priorities. Organisations that adopt agent-driven ETL and ELT will get this layer almost for free. Those still relying on human-built pipelines will need to treat metadata as code: when a pipeline is deployed or a schema changes, an automated process updates the graph as part of the deployment workflow. Without this automation, the graph becomes a static catalog that decays on arrival.
The Logical Layer tells you how things connect across siloed systems, and in a federated enterprise, this is where the hard work of interoperability happens. Semantic models and views that define how raw tables are joined for business use. Entity resolution mappings that connect records across systems to the same real-world entity. Business process diagrams showing data flow.
In a federated enterprise, different domains (Sales, Logistics, Finance) often use different terminology for the same concept. A “Client_ID” in Sales and a “Ship_To_Party” in Logistics and a “Billable_Entity” in Finance may all refer to the same customer. The logical layer maintains these translation keys, allowing agents to query across domains without physical data consolidation. Each domain retains ownership of its data and schemas, but the graph holds the mappings. The graph does not recentralise anything. It federates.
Here’s the uncomfortable truth: this is where agents struggle most with human-built systems. There is someone, somewhere in the organisation who is aware of these mappings. It’s in their head, or scattered across Confluence pages that may not be visible to agents due to organisational boundaries. Depending on the organisation’s maturity, this information might exist in metadata stores under business metadata, or it might not exist in any structured form at all.
There are practical approaches to bridging this gap. Some implementations use sampling-based discovery on initialisation: agents probe data sources to identify implicit foreign key relationships that were never formally documented. Over time, agent interactions with users surface additional mappings. When an analyst tells an agent that “Client_ID in Sales is the same as Account_Holder in Risk,” that correction flows into the logical layer as a validated mapping. The agent’s memory becomes a feed for the very metadata it depends on, another instance of the compounding effect at the heart of this architecture.
Business Metadata: The Semantic Layer
This is where you encode what things mean in your organisation. Without it, agents cannot distinguish “revenue” in the accounting sense from “revenue” in the product analytics sense. They cannot know that “Employee” and “Staff” refer to the same concept, or that a particular dataset falls under specific regulations. There have been many attempts to define semantic layers over the years, sometimes at the BI level, sometimes at the ETL layer. Getting it right and keeping it maintained has always been hard. Now, with agents depending on it, the stakes are higher.
What to capture: business glossary terms with authoritative definitions, ownership, and scope. KPI definitions, including precisely what “active user” means, how “churn” is calculated, what “ARR” includes, and where these definitions vary by region or business unit. Domain taxonomies and ontologies (SKOS, OWL, or simpler structured vocabularies where formal ontologies don’t yet exist). Data classification, compliance, and security metadata: sensitivity levels, access entitlements, regulatory tags, encryption requirements, and the policies that govern them. Ownership and stewardship metadata, so that every node in the graph has an accountable human.
For organisations with the maturity, moving beyond a business glossary toward a formal ontology is where the real precision lives. A glossary tells you what “Director” means. An ontology tells the system that “CEO” is a subclass of “Executive” which is a subclass of “Employee,” enabling inference without explicit instruction. Property graphs provide flexibility for the edges and traversals. RDF-style rigour provides precision for core definitions. The two are complementary, not competing. In reality, building an ontology takes time and effort. The practical path is: define a business glossary first, then extend to a controlled vocabulary, then lightweight ontology for your most critical domains, then formal ontology where inference value justifies the effort.
When an agent is asked to “analyse churn in the EMEA region,” it uses the semantic layer to resolve the ambiguity of “churn” (voluntary cancellation or non-renewal?) and “EMEA” (which specific countries are currently included in the EMEA sales territory, since this may differ from organisation to organisation). This semantic grounding is what prevents generative models from hallucinating plausible but wrong answers.
A critical point, and one the industry is learning the hard way: ontology, linking, and semantic definitions must be defined by domain experts and business stakeholders, not by developers working alone and certainly not by LLMs. Modelling data in a business domain takes business knowledge, which usually lives in the “tribe.” The technical implementation comes later. Today there is a dangerous temptation to let LLMs generate ontologies or to let developers improvise based on what works in a prompt. LLMs amplify the gap between demo and production: they produce confident, well-structured output that looks right, making the failure mode harder to detect. The risk is mistaking early fluency for understanding. This becomes a bigger problem when dev, test, and production environments don’t match: a hot fix that hasn’t been propagated will make agents’ lives highly challenging. Therefore, humans should always be in the loop for semantic definitions until a reliable meta knowledge graph is established and validated.
Operational Metadata: The Operational Layer
This layer captures how data is actually used and how healthy it is. I group behavioural signals (usage patterns, query logs, process traces) together with quality and lifecycle signals because in practice they serve the same purpose: telling agents how much to trust a particular asset and how to use it effectively.
What to capture: query logs from analytical engines (which tables are queried, by whom, how often, and in what combinations). Dashboard and report usage. Data access patterns across teams. The join patterns analysts actually use versus those documented. Collaboration and process traces: who approved which workflow, how long typical processes take. Data quality metrics: validation scores, error rates, completeness. Freshness indicators. Lifecycle status: experimental, production, deprecated, archived. Incident and anomaly logs linked to impacted datasets. Cost metrics.
A derived “trust score” for each dataset, combining freshness, quality pass rates, and usage patterns, gives agents a reliability signal. The trust score should be multi-signal and auditable: usage frequency alone is a weak signal unless backed by quality and freshness, and weighting popularity too heavily creates the feedback loops described in Part 3’s “What Can Go Wrong” section. Concretely, this means connecting the outputs of your existing monitoring tools directly into the graph: when a quality check fails, the graph should automatically flag the affected assets.
This layer also extends to agent behaviour. Every time an agent reasons through a problem, that trace should be recorded. Successful runs reinforce patterns. Runs needing intervention highlight anti-patterns. Each agent interaction automatically enriches this layer, meaning the graph grows more valuable with use, not just with manual curation.
Agentic Metadata: The Decision Trace Layer
Perhaps the most novel and ultimately most valuable component is what I call agentic metadata: the metadata that only exists because agents are operating. This is the explicit capture of actions, tools used, policies applied, and outcomes from both AI agents and human operators. When a loan application is approved, the graph does not merely update the application status. It creates a decision event node, linking the application to the specific version of the credit risk policy used, the model inference result, and the human officer who reviewed the edge case. This decision lineage transforms the graph from a map of “what is” to a map of “why it is.”
This is the write-heavy layer of the architecture. The ingestion mechanism matters (covered in Part 3), but the principle is clear: every agent action, successful or failed, must be captured with its reasoning steps, outcome, and crucially, any human-in-the-loop correction. When a human corrects an agent, that correction is the most valuable signal in the entire graph, because it represents the moment where institutional knowledge is made explicit.
These corrections rarely stay confined to one layer. When a domain expert corrects an agent’s metric definition, that correction updates the semantic layer (the authoritative definition changes), may revise the logical layer (if the correction implies a different join or entity resolution), and feeds back into the operational layer (trust scores adjust for affected assets). A single human correction can ripple across all four metadata categories, which is precisely why the graph structure matters: the relationships between layers ensure that a correction in one place propagates to everywhere it is relevant.
Traditional metadata frameworks have no category for this. In a restaurant, nobody writes down that the Tuesday fish supplier is unreliable, or that Table 12 always orders the wine before the starter. The staff just knows. Until someone leaves and takes that knowledge with them. Agentic metadata is the enterprise equivalent: the knowledge that only exists because people, and now agents, are doing the work. Technical metadata captures structure. Business metadata captures meaning. Operational metadata captures health. Agentic metadata captures intelligence: what was decided, what was tried, what worked, and what a human corrected. It is the layer that enables experiential learning at the enterprise level.
Connecting the Layers
Each layer is valuable independently, but the power comes from relationships spanning across them. Technical schema nodes link to business terms. Business terms link to policies. Data assets link to the people who use them and the processes that created them. Decision traces connect to the data consumed and outcomes produced.
Consider a knowledge graph builder agent asked to model “customer transactions” for a fraud detection schema. Without the meta knowledge graph, it guesses at entity types and relationships based on the document alone. With the graph, it traverses: the enterprise ontology (where “Customer” is already defined and linked to “Account” and “Transaction”), the logical layer (where entity resolution maps “Client_ID” in one system to “Account_Holder” in another), a prior decision trace (where a previous project learned to model “Movement” as a separate node, not a property), and a policy node (marking certain fields as PCI-DSS restricted). The agent proposes a schema grounded in the organisation’s accumulated context, not just the current document.
Looking forward, this same graph structure naturally extends to AI and ML governance. Model versions, training data lineage, feature definitions, and inference performance metrics can all be represented as nodes connected to the decision traces they inform. This is not required on day one, but the architecture should be designed with this extensibility in mind.
In a mature deployment, the meta knowledge graph will not be a single monolithic structure. Different agents will manage different slices: a data quality agent owns the operational layer for its domain, a compliance agent owns the policy subgraph, a schema builder agent maintains the technical metadata for its pipelines. Think of it as a restaurant group where each kitchen has its own sous-chef responsible for their station, but they all share the same recipe book and supplier list. When two agents reach conflicting conclusions, say one defines “active customer” by login frequency and another by transaction volume, they surface the conflict rather than silently picking one. A human in the loop defines the goal: which metric matters for this context? The agents then update their respective graph slices to reflect the resolution, and that resolution becomes a precedent for future conflicts. The human’s role is not to resolve every question, but to set the parameters within which agents can resolve questions themselves.
The Virtualisation Principle: Data Stays, Intelligence Moves
The meta knowledge graph does not replicate your data. It virtualises it. Data stays where it lives: in the lakehouse, in the OLTP system, in the graph database, in the warehouse. The meta knowledge graph stores the metadata, the relationships, the semantics, and the decision context. It holds pointers, not copies.
The pattern extends a broader shift already underway. The industry is moving toward architectures where analytical query engines sit directly over operational storage, where graph query layers sit over lakehouse tables, and where some architectures are beginning to run OLTP workloads over open table formats without separate database infrastructure. The common principle is to eliminate data movement. Every copy is a liability: staleness, cost, governance overhead, drift. The meta knowledge graph takes this principle further by virtualising not just the data, but the context that makes the data usable.
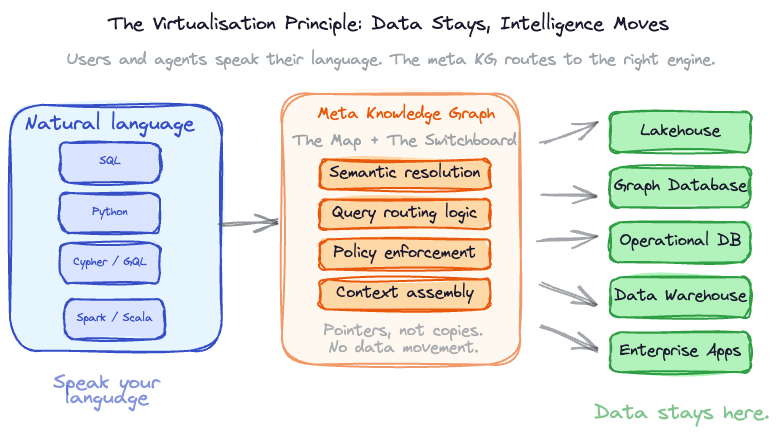
The practical implication is significant, and it is one that most discussions about context graphs overlook. A user or agent should be able to ask a question in whatever language they are most comfortable with. SQL, GQL, Cypher, Spark, Python, or plain natural language. What processing framework or query engine runs behind the scenes should eventually not matter and will be hidden from the user. An analyst who thinks in SQL should not need to learn Cypher to traverse lineage. An agent that reasons in natural language should not need to know whether the answer comes from a graph traversal, a warehouse query, or a combination of both. The meta knowledge graph, combined with the virtualisation layer, acts as the universal interface: it resolves the question into the right queries against the right engines, assembles the context, and returns a grounded answer.
None of this is fully realised today. But the trajectory is clear, and architectures designed now should anticipate it. The meta knowledge graph is the natural place to hold the routing logic: it knows which assets live where, which engines serve which workloads, and which query patterns have worked in the past. It is both the map and the switchboard. Further, it can factor in cost metrics: which query is cheapest to serve, which engine handles this workload most efficiently, and whether the answer justifies the compute cost of a multi-hop traversal versus a simpler lookup.
Research into graph-native neural architectures, including attention mechanisms that can focus directly on relevant nodes without requiring explicit traversal paths, points toward a future where retrieval from the meta knowledge graph becomes faster and more adaptive than today’s query-plan-and-execute approach. This is still early-stage work, but it reinforces the design principle: invest in the graph structure now, because future retrieval methods will extract more value from it, not less.
This also has implications for who can adopt this architecture first, and when.
The Chicken-and-Egg Paradox
There is an irony at the heart of this architecture that is worth confronting directly.
When we have a fully agent-driven data ecosystem, we are likely to have near-perfect metadata. It is far easier to tell a piece of software to capture all of its actions, log its decisions, and register its outputs than it is to ask a human who is under time pressure to deliver the pipeline and move to the next project. Agents are inherently better metadata citizens than humans. They don’t skip the documentation step because they’re rushing to hit a deadline.
But here’s the paradox: in order to have a fully agent-driven data ecosystem, you need a reliable meta knowledge graph already being functional. Agents need the context to operate, but the best way to generate that context is to have agents operating.
It’s like opening a restaurant with no recipes, no supplier list, and no knowledge of what your regular guests prefer, but expecting the food to be excellent from the first service. You need experience to be good, but you need to start cooking to get experience.
This is a chicken-and-egg problem, and it has real consequences for who can adopt this architecture first. Digital-native organisations and new startups will find this significantly easier. They can build agent-driven ETL/ELT environments from the ground up, where metadata capture is baked into every pipeline from day one. They don’t have decades of legacy systems, undocumented transformations, and tribal knowledge locked in the heads of people who may have already left the company.
Large enterprises face a harder path. Their existing data estates were built by humans, for humans, with metadata treated as a secondary concern. The tribal knowledge that agents need to function is scattered across Confluence pages, Slack channels, code comments, and the memories of individuals who may not even be in the same team anymore. Retrofitting this into a structured, queryable graph is real work, and it won’t happen overnight.
The practical implication: large enterprises will need to be more disciplined about starting narrow. The virtualisation principle helps here: you don’t need to migrate data into a new system or rewrite your pipelines. You build the intelligence layer on top of what you already have. Pick the workflows where you can instrument from scratch. Use agents to build new pipelines (where they capture their own metadata naturally), while gradually enriching the graph with context harvested from legacy systems. Over time, the agent-driven portion of your estate grows, the metadata quality improves, and the chicken-and-egg problem resolves itself incrementally.
The organisations that wait for perfect metadata before deploying agents will wait forever. The organisations that deploy agents and let them contribute to the metadata as they work will compound their way to the architecture described in this series.
In Part 3, I’ll provide a concrete metamodel you can start building from, cover governance (including why agent memory must be treated as authority, not documentation), address tribal knowledge capture, operating model, failure modes, and the practical path to getting started.